

Вижу, потребность в материале есть, предварительно пообщался с Сергеем Кокшаровым, авторы не против публикации. Курс закрывает такие важные в работе каждого владельца сайта вопросы:
- Как грамотно спроектировать структуру сайта?
- Какие приемы позволят выделить в ней приоритетные кластеры?
- Как объяснить копирайтеру, что именно вам нужно и организовать контролируемые процессы?
Ведущие курса:
- Игорь Рудник,
- Сергей Кокшаров aka Devaka,
- Игорь Горбенко.
Автор конспекта: Александр Сопоев, SEO-специалист.
Курс проходил давно. Это моментами видно в конспекте — уже неактуальны фрагменты с Яндекс.Каталогом, DMOZ, … Зато в целом он не утратил свою актуальность и полезен. Рекомендую.
- Создание структуры сайта
- Поиск конкурентов
- Рейтинги сайтов
- Анализ ТОПа в выдаче ПС по основным запросам
- Использование сервисов
- Анализ структуры конкурентов
- Цели
- Процесс
- Как выгрузить структуру конкурентов (разные варианты)
- Типовые ошибки
- Формирование максимально широкой структуры сайта
- Процесс
- Расширение структуры на основе пользовательского спроса
- Оценка конкуренции кластеров запросов
- Оцениваем ТОП по основному запросу
- Оценка информационных запросов
- Критерии оценки конкуренции запросов
- Поиск молодых сайтов и их анализ
- Цель
- Процесс
- Какие данные собираем
- Съём данных
- Техническое задание на написание текстов
- Создание ТЗ для информационного сайта / под статью
- Разбираем пример ТЗ для сайта по акне (о лечении кожи)
- Пример процесса создания ТЗ:
- Систематизируем
- Создание ТЗ для интернет-магазина
- Сезонность
- Пример процесса создания ТЗ
- После того как запросы были собраны:
- Определяем оптимальный объем текста (/статьи) на странице
- Подход «Здравый смысл»
- Аналитический подход «Анализ ТОПа»
- Технические параметры текстов
- Основные
- Вторичные, но важные
- Пример проверки статьи на технические параметры
- Нетехнические параметры текста
- Стиль
- Структура и элементы
- Шрифты
- Инструкция по написанию статей — для копирайтера
- Структура инструкции
- Дополнительно можем указать:
- Фотографии
- Какие фото брать?
- Где взять фото?
- Уникализируем фотографии
- Роль структуры (семантического проектирования) в прототипировании сайта
- Как делать прототипы (минимально достаточные прототипы)
- Десктоп
- Онлайн
- Итоговая документация
- Пример прототипа
- Примеры хорошей структуры
- LSI-тексты
- Введение
- Методы получения LSI-фраз
- Анализ спроса
- Поисковые подсказки
- Рекомендации в поиске
- Яндекс.Вордстат (или Google Keyword Planner)
- Анализ текста
- На выдаче
- Тексты сайтов
- Анализ семантических связей
- LSI Graph для англоязычной семантики
- Минимальный набор, который понадобится
- Excel
- Проверка пользы по LSI
- Полезный инструментарий
- Advego
- ContentYoda
- Text.ru
- Главред
- Углубленный анализ конкурентов (при помощи Serpstat или другого аналогичного инструмента)
- Пример — анализ конкурентов в Serpstat
- Кластеризация запросов
- Теория кластеризации
- Кластеризация по ТОПу поисковой выдачи
- Сервисы кластеризации
- Практика — проверка совместимости запросов
- Выбор автора
- Введение
- Где искать
- Традиционные каналы
- Альтернативные источники авторов
- Пример — поиск кровельщика
- Пример размещения вакансии на сайте работы
- Текст вакансии для поиска автора
- Разные площадки — разные объявления
- Тестируйте
- Тестовая задача копирайтеру
- Пример:
- Таблица для ведения учёта
Создание структуры сайта
Автор — Игорь Рудник.
Этот блок состоит из 6-ти частей. Рекомендация — изучать в представленной очерёдности:
- Поиск конкурентов. Разбираем: как искать конкурентов, какими методами пользоваться и как в итоге сформировать их список.
- Анализ структуры конкурентов. Анализируем наиболее мощных конкурентов.
- Формирование максимально широкой структуры сайта.
- Расширение структуры на основе пользовательского спроса. Оптимизация, отсеивание лишних и добавление нужных страниц.
- Оценка конкуренции кластеров запросов. Чтобы понять на какие кластеры сделать акцент. Поиск молодых сайтов и их анализ.
- Выбор менее конкурентных кластеров запросов. Определить наиболее приоритетные направления, которые быстрее дадут отдачу в виде трафика и денег.
Поиск конкурентов
Учимся как искать конкурентов. Как находить тех с кем нам придётся дальше работать. Как находить не только прямых конкурентов, но и косвенных и что с ними дальше делать.
Рейтинги сайтов
Возможно Вы уже забыли про их существование, но, тем не менее, люди ими пользуются и там можно находить интересные ресурсы о которых Вы не могли догадаться, что они существуют:
- liveinternet.ru
- hotlog.ru
- top100.rambler.ru
- top.mail.ru
Анализируем их — смотрим какие конкуренты есть по нашей тематике.
Рейтинг Рамблера удобен, есть информация о трафике (посетителях, просмотрах). Нас интересуют сайты, у которых более-менее приличный трафик (на примере ювелирного агрегатора — от 1000 в сутки), мы переносим их в нашу таблицу.
Анализ ТОПа в выдаче ПС по основным запросам
- Главный запрос сайта или раздела.
- Выгружаем ТОП-20.
- Формируем лист.
Пример — ювелирный агрегатор. Одно из основных его направлений — кольца. Вбиваем запрос «купить кольцо» и смотрим ТОП-20 — какие там основные сайты. Выгружаем их в Excel-таблицу. И то же самое делаем ещё по нескольким запросам — пробиваем основные разделы («купить цепочку», «купить серьги»). Делаем это в разных поисковых системах. Таким образом сформировываем лист.
Использование сервисов
Выгружаем из Serpstat всех конкурентов в ПС и из контекстной рекламы. Смотрим что там за сайты крутятся.
В Semrush смотрим конкурентов в Гугле по общим запросам.
Также можем посмотреть и в Similarweb.
Далее для более удобной работы с выдачей Яндекса есть инструмент Арсенкин. Через него также можно посмотреть ТОП и можно сразу выгрузить его в файл .csv
Да, хотя Serpstat и Арсенкин по идее делает одно и то же, но Игорь предпочитает выгружать и там и там, так как здесь у нас Serpstat показывает не конкретно по выдаче конкурентов, а по пересечению фраз, а в Арсенкин данные конкретно по выдаче (соответственно данные могут разниться).
Потом вручную смотрим выдачу по Гуглу и выписываем конкурентов.
В итоге мы должны составить таблицу (образец).
Затем объединяем собранное в одном столбце, удаляем дубли. В итоге у нас получается список конкурентов с которым мы будем в дальнейшем работать. Таким образом мы проводим анализ конкурентов — просто делаем их сбор без анализа кто сколько собирает трафика и т.д. (пока что нам это не нужно, важно — просто изучить нишу, собрать всех конкурентов и сделать первичный анализ — посмотреть где кто находится, поклацать сайты, увидеть какие у них разделы и т.д.)
На следующих шагах мы будем анализировать этих конкурентов на предмет структуры и будем формировать структуру под собственный сайт.
Анализ структуры конкурентов
Цели
- определить типы посадочных страниц конкурентов,
- количество посадочных страниц,
- определить уровни вложенности,
- упростить дальнейший сбор и продумывание семантики.
Процесс
- Создаем таблицу GoogleDocs.
- Делаем вкладку под каждый сайт конкурентов (который мы ранее выделили как наиболее крупный и интересный для нас).
- Выгружаем структуры конкурентов.
Как выгрузить структуру конкурентов (разные варианты)
- копируем с веба (из меню),
- выгрузить html-карту сайта,
- через сервисы,
- при помощи софта.
Типовые ошибки
- Упускаются разделы сайтов,
- Используется малое количество сайтов (нужно брать не один-два сайта, а больше и по каждому из них смотреть какие у него преимущества и смотреть для себя наилучшие решения),
- Не используются мультирегиональные сайты.
Пример: структура ювелирного агрегатора.
Нужно рассматривать не только сайты, которые напрямую относятся к нашей нише, но и агрегаторы — так как они тоже будут нашими конкурентами.
Визуальный анализ. Нам необходимо выгрузить абсолютно все категории, которые мы найдём, в данном случае (рассматриваем сайт gold.ua — Производители, Металл и др.). Почему мы не выгрузили цены из фильтрации? Потому что под них невозможно найти поисковые запросы — никто так не ищет и, кроме того, мы видим что эти страницы закрыты от индексации, её нет в индексе (проверили в RDS-баре — видим, что gold.ua делал эту фильтрацию по цене не для сбора трафика, а для удобства человека, нам нет никакого смысла добавлять эту страницу в свой список.
У агрегаторов смотрим метки (теги), смотрим какая структура, какие фильтры есть, анализируем какие из них индексируются, а какие не индексируются, и на основании этого также сводим единую структуру.
Потом на основе этих данных мы будем формировать свою структуру.
Можно использовать для этого разные онлайн-сервисы — например, Serpstat или Semrush. Смотрим уровни вложенности и распределение трафика. Таким образом можем понять иерархию сайта — как всё устроено, как работает, как оптимизируется.
Можно использовать программы (Screaming Frog | Netpeak Spider | PageWeight), для того чтобы распарсить сайт и посмотреть какие страницы есть. По входящим ссылкам можно понять какие страницы наиболее популярны и важны на сайте (в структуре). Можем отсортировать, увидеть фильтры, иерархию.
В целом этого инструментария достаточно, чтобы посмотреть сайты конкурентов, проанализировать и составить документ с которым мы дальше сможем работать.
Формирование максимально широкой структуры сайта
Задача адаптивная, нужно просто обработать тот массив данных, который мы создали на прошлом шаге.
Процесс
- Соединяем все уникальные разделы в один документ (в одну вкладку).
- Дополняем каждый раздел за счёт конкурентов.
- Формируем максимально полную структуру.
Отталкиваться лучше всего от того сайта, который имеет наиболее широкую структуру. Удаляем дубли в содержимом раздела (быстрее всего в Excel). Объединяем в один столбик. В итоге получится максимально большой и полный перечень.
Не факт, что под всё есть поисковые запросы, но сейчас задача стоит собрать максимально полную структуру. А не следующем шаге мы будем её анализировать — нужны ли все эти страницы и нужны ли какие-то дополнительные.
Ремарка — в данном контексте мы рассматриваем интернет-магазин, но для сайта информационного — процесс аналогичный. Просто берём другой тип сайтов и больше внимания обращаем на сами статьи, так как там это страницы которые собирают больше всего трафика. Но мы также выделяем рубрики, внутренние рубрики и статьи. И также объединяем и находим все темы.
Расширение структуры на основе пользовательского спроса
На этом этапе парсим ту структуру, которую мы подготовили на этапе анализа конкурентов (и мозгового штурма).
В КейКоллекторе:
- Перемножаем запросы.
- Формируем группы (Игорь не рекомендует использует более 200 групп, так как могут быть проблемы со скоростью работы КК).
- Переходим к парсингу.
После сбора смотрим по Базовой частоте есть ли спрос, если есть — оставляем, если нет — убираем. Видим что в группе собралось много запросов. Видим определённые тенденции, например — в собранном в группе «бриллиант кольцо золото» также отчётливо прослеживаются и запросы с «помолвочное». Чтобы принять решение выносить ли в отдельную группу — собираем точную частотку.
Проходим по всем группам, принимаем решение по каждой из них, чтобы ускорить — можно отсортировать группы по количеству запросов в них.
После того как мы оценили наши запросы, выделили группы которые нам нужны, отметили запросы которые нужно распределить на несколько групп (например думаем а не выделить ли отдельную группу запросы с «белое золото», чтобы понять масштаб — можно сделать глобальный фильтр по всем группам и посмотреть сколько запросов во всех группах).
Нумеруем, чтобы в дальнейшем её использовать и не запутаться:
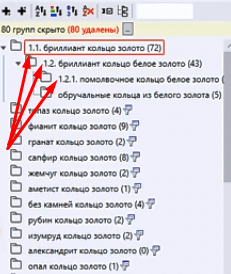
После того как мы сформировали перечень наших групп — мы их вносим в структуру:

Группы в структуре нужно также пронумеровать.
Написанная выше механика позволяет определить какие запросы важны и правильно расставить приоритеты — какие страницы нужны, а какие не нужны.
Оценка конкуренции кластеров запросов
Делаем выбор менее конкурентных кластеров запросов, что может сильно помочь более быстро развивать бизнес, быстро наращивать обороты.
В этой части:
- Оцениваем ТОП по основному запросу.
- Оценка кластера запросов.
- Критерии оценки конкуренции.
Оцениваем ТОП по основному запросу
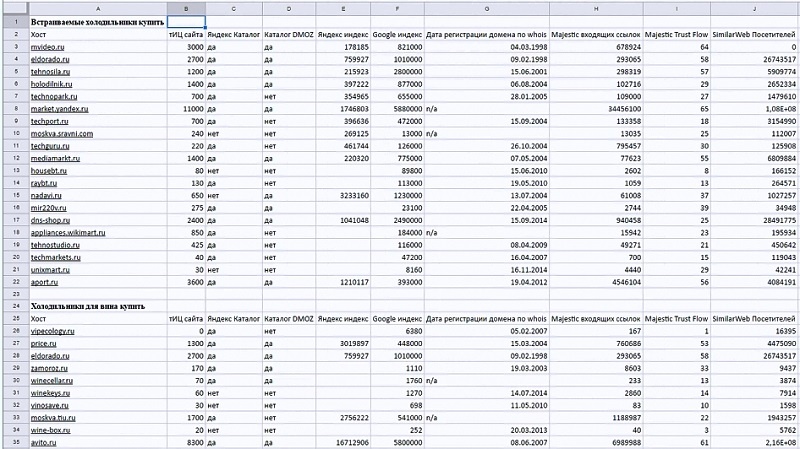
Используем Арсенкин для выгрузки ТОПа.
Потом CheckTrust, в котором смотрим на:
- Whois дату (сколько лет сайту),
- Trust Flow (ссылочное качество, насколько сильные ресурсы находятся в этом ТОПе),
- Посетителей (трафик по SimilarWeb позволяет косвенно понять что это за сайты и какие игроки крупные).
Делаем выгрузку. Анализируем сайты.
Когда в ТОП находим, среди прочих, молодые сайты, смотрим:
- что это за сайты,
- какие у них есть страницы,
- как они продвигались.
Это поможет понять — сможем ли мы по данному кластеру запросов войти в ТОП.
- Заходим на сайт, осматриваем его.
- Смотрим тенденцию трафика через расширение браузера Similarweb.
- Заходим в Semrush и смотрим там информацию по Google-трафику сайта, запросы и позиции.
- Смотрим по Serpstat’y по Яндексу по каким запросам данный сайт в ТОПе.
Наша задача при анализе кластеров:
- найти молодые сайты,
- в целом оценить нишу.
На скрине примера ниже:
- «тИЦ сайта», «Яндекс Каталог» и «Каталог DMOZ» — уже не используем,
- можно добавить столбец «ИКС».
Сейчас невозможно оцифровать конкуренцию (по кластеру запросов вывести примерную цифру, допустим 15 по 50-ти балльной системе), потому что всё персонализировано и нужно оценивать отдельно.
Таким образом мы выделяем кластеры и для себя определяем приоритет какие направления лучше всего продвигать. Расставляя правильно приоритеты на этапе оценки поисковых запросов и их конкуренции — мы для нашего бизнеса делаем огромный вклад в его дальнейший успех, так как усилия, которые будем прилагать, дадут более быструю отдачу.
Оценка информационных запросов
Сервис Mutagen. Единственный недостаток — формула оценки скрыта. По крайней мере 50% запросов оценивает он верно.
Он показывает одну цифру конкуренции. Не показывает конкуренцию если она превышает порог «25». Сервис нацелен на то чтобы выбрать наименее конкурентные запросы.
Принято смотреть на запросы меньше показателя «15», но в этом случае получается что по факту мы отсеиваем из нашей статьи наиболее трафиковые запросы и теряем определённые ключевые слова и в итоге наша статья получается менее полная по семантике. Поэтому на данный цифровой критерий можно опираться при оценке кластеров, но не нужно (по причине высокого показателя конкуренции) выкидывать из семантики какие-то слова.
Критерии оценки конкуренции запросов
- Количество главных страниц в ТОП-10
Заходим в Яндекс и смотрим выдачу по запросу — количество главных/внутренних под этот запрос. Это один из показателей конкуренции, если под определённый запрос у нас выдаются главные страницы (если под эти запросы затачиваются отдельные сайты) — значит что в нише сильная конкуренция.
- Количество вхождений запросов в title ТОП-10
Оценить это можно в КейКоллекторе.
Игорь рекомендует отсеивать запросы когда вхождений более «7».
Поиск молодых сайтов и их анализ
Цель
- Найти молодые растущие сайты.
- Проанализировать их растущие страницы.
- Учесть типы растущих страниц при проектировании.
Процесс
- Используем список конкурентов, которых мы ранее нашли.
- Собираем данные.
- Анализируем.
Какие данные собираем
- дату регистрации домена по whois,
- количество проиндексированных страниц,
- трафик по Симиларвеб (обязательно),
- самые молодые и имеющие трафик сайты изучаем подробно.
Съём данных
- RDS bar
- checktrust.ru
Игорь рекомендует пользоваться Чектрастом — он онлайн и достаточно дешёвый. В него загружаем наш список конкурентов, отмечаем «Дата регистрации домена по whois», «SimilarWeb трафик с поиска» и «SimilarWeb Посетителей»:

Нас интересуют молодые сайты, поэтому фильтруем — сортируем по дате регистрации:
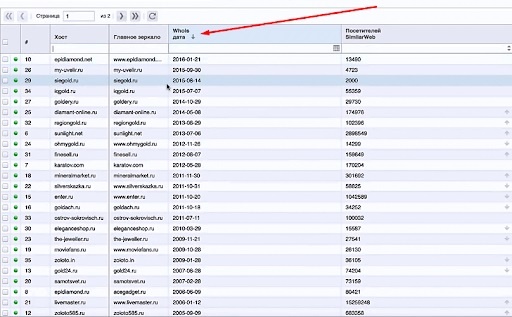
Далее смотрим на определённое отношение даты регистрации и трафика. Посетители там отображаются за последние 30 дней.
До какого края опускаться по возрасту? Желательно — за последние 2 года, максимум 3.
Больше всего нас интересует динамика сайтов — динамика трафика. Плагином SimilarWeb смотрим динамику. Не всегда можно доверять данным из одного источника — поэтому идём в Semrush, и там смотрим динамику по домену.
Видим что динамика трафика у сайта положительная — значит можем рассматривать его дальше.
Дальше — мы смотрим какие страницы наиболее популярные.
Обращаем внимание какие страницы больше всего трафика собирают. Смотрим в Semrush, если видим что на главную идёт больше всего брендового трафика — это не очень хорошо, желательно находить примеры где трафик больше всего рассаживается по внутренним страницам.
На основе этих данных уже можно при проектировании структуры отметить на какие рубрики стоит сделать акцент и, допустим, их первыми запускать в производство и для них первыми готовить тексты и так далее.
Ещё мы можем поискать сайты по дополнительным направлениям — через Арсенкин выгрузить ТОП-100 сайтов и все эти сайты, опять же, закидываем в ЧекТраст. Увидев подходящие сайты для анализа — смотрим сайт, находим популярные страницы, которые растут, оцениваем затем конкуренцию этих запросов. Если всё ок — то необходимо сделать дополнительный акцент при продвижении сайта на эти страницы. Дополнительный акцент — написать на них более объёмные тексты или сделать на них дополнительную внутреннюю перелинковку. Таким образом, если это не достаточно конкурентные страницы, можно быстрее получить на них трафик и начать зарабатывать на них деньги.
Дополнительно можно этот сайт добавить в Serpstat, посмотреть динамику сайта (что он растёт). Можно посмотреть «Страницы с наибольшей видимостью» (они отличаются от тех что показывал Семраш — здесь проверка по Яндексу и позиции могут отображаться другие чем при проверке по Google).
Анализируйте Ваших конкурентов, находите точки роста.
Техническое задание на написание текстов
Автор — Игорь Рудник.
Создание ТЗ для информационного сайта / под статью
Перед тем как перейти к созданию ТЗ мы должны были пройти предварительные этапы.
Порядок работ:
Проанализировали структуры конкурентов.Разработали первую структуру будущего сайта.Расширили структуру на основе пользовательского спроса.Сделали итоговую структуру.- Создаём ТЗ под каждую страницу.
Структура информационного сайта, в отличии от коммерческого, имеет сильно меньше проработки, потому что здесь основной упор на статьи, а не на рубрики. То есть тут рубрики определяют какие у нас будут разделы, но они, как правило, не собирают трафик. Поэтому проработка структуры для информационного сайта обычно менее важна. Гораздо более важно — какие темы мы выбрали для работы.
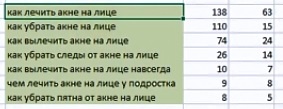
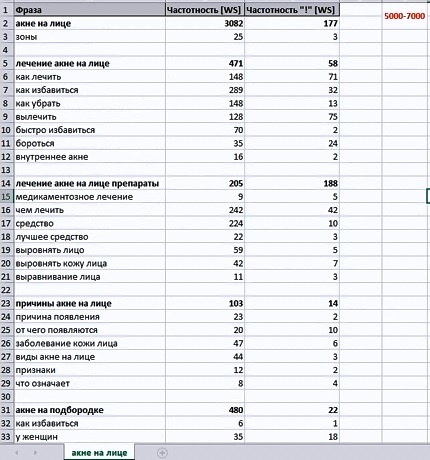
Разбираем пример ТЗ для сайта по акне (о лечении кожи)
Мы выделили темы, спарсили их. И переходим к формированию ТЗ.
Вот пример того что мы получаем в итоге:
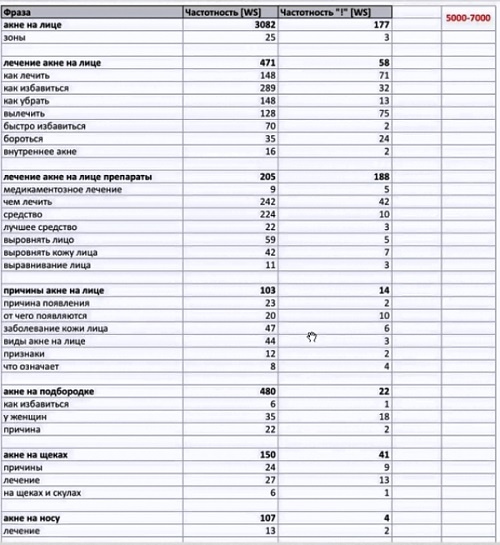
Тут:
- главный запрос, его частота,
- второстепенные запросы, которые мы будем использовать в <h2>,
- «хвосты», которые мы будем использовать в статье.
Пример процесса создания ТЗ:
- Парсим запросы.
- Удаляем пустые запросы. Обычно, если у нас широкая тематика, можем смело удалять то что у нас меньше пяти по точной частоте.
- Удаляем по KEI в КейКоллекторе. Рассчитываем KEI по параметру — отношение базовой частоты к точной (KEI = базовая частота / точная частота).
Зажимаем клавишу «Shift» и рассчитываем KEI для всех вкладок. C помощью «Shift» делаем пакетно для всех групп. Чистим также пакетно с помощью этой клавиши, что позволит не тратить время.
Когда видим большую базовую частоту и при этом весьма малую точную — этот запрос, скорее всего сильно конкурентный и при этом имеет очень мало трафика. Такие запросы нам продвигать неэффективно — поэтому мы удаляем KEI больше 40 (в обычном случае). - Удаляем коммерческие запросы — с «купить», «цена» и прочие. Чтобы быстро это сделать — мы идём в анализ групп и смотрим что у нас осталось.
- Выгружаем из КК, чтобы сделать это правильно (со всеми группами) — зажимаем всё тот же «Shift».
- Группируем внутри группы — по смыслу, по пользовательскому интенту. Группируем в Excel, через «Найти все», отмечаем разными цветами разные группировки, потом сортируем по цвету. Проходя по кластеру оставляем только нужные слова.
Было:

Стало:

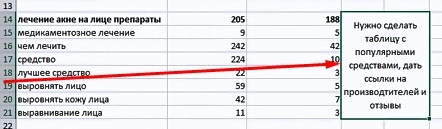
Таким образом проходим и определяем логические группы. После такой группировки определяем структуру статьи из блоков. Благодаря этому автор будет понимать о чём писать статью. Для выстраивания логики статьи — позволяем автору менять блоки местами . - Формируем ТЗ.

Формирование такого ТЗ занимает много времени. Но когда даём автору ТЗ в таком виде — он понимает о чём писать и будет использовать выделенные слова. Как результат — получаем хорошую структурированную статью, которая будет собирать трафик. Такие статьи практически всегда выстреливают. Вероятность того что они будут собирать трафик сильно выше чем если бы Вы просто дали тему с выгрузкой запросов и сказали написать статью.
Иногда необходимо давать комментарии к группам, пример:

Таким образом мы даём более структурированную информацию и создаём больше ценности. Автор данную часть текста проработает более качественно и в итоге эта статья будет написана лучше чем если бы мы не дали комментарий.
Но часто инструкция по работе со статьями экономит время и нам не нужно писать эти комментарии.

Систематизируем
Номер ТЗ = Номер статьи = Номер в таблице учёта.
Желательно чтобы номер был связан также и с рубрикой. Пример — 1.1, 1.2, 1.3, …, в котором первая цифра «1» — связана с конкретной рубрикой.
![]()
Создание ТЗ для интернет-магазина
Перед тем как перейти к созданию ТЗ мы должны были пройти предварительные этапы.
Порядок работ:
Проанализировали структуры конкурентов.Разработали первую структуру будущего сайта.Расширили структуру на основе пользовательского спроса.Сделали итоговую структуру.- Создаём ТЗ под каждую страницу.
Рассмотрим на примере ТЗ для ювелирного агрегатора, возьмём локальную задачу — структура раздела «Кольца» и посмотрим как из страниц формируется ТЗ, какой в итоге у нас должен получиться файл.
Структура раздела «Кольца» на входе:

Одна из веток выглядит вот так:
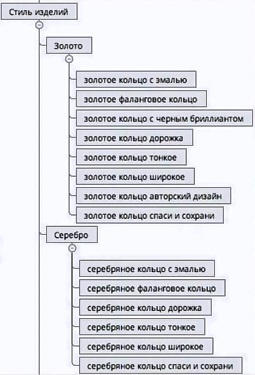
Но, здесь есть одна ошибка — все эти ветки не пронумерованы. Должно быть — «1. Стиль изделий», «1.1. Золото», «1.1.1. Золотое кольцо с эмалью», «1.1.2. Золотое фаланговое кольцо» и так далее. Эта нумерация должна быть сквозной и использоваться затем и в ТЗ.
В итоге вот так будет выглядеть ТЗ под страницы когда у нас небольшие кластеры запросов:
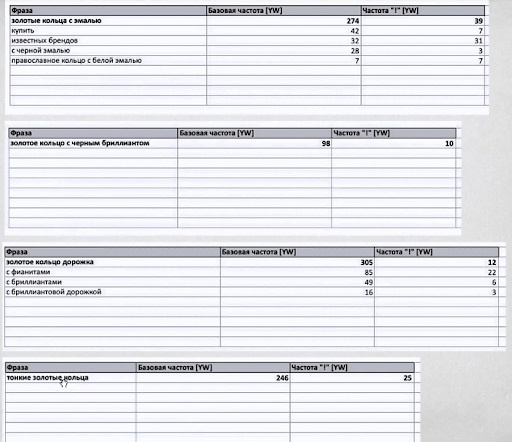
А вот так выглядит ТЗ для более крупного запроса:
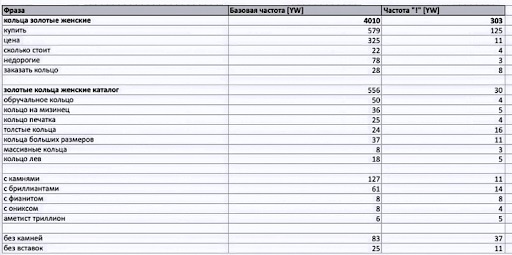
Разбираем пример:
- Основной запрос — «кольца золотые женские». Он используется в title и заголовке h1. Под этот запрос затачивается вся страница.
- В h2 — «золотые кольца женские каталог». Этот запрос должен обыгрываться — позволяем наших копирайтерам склонять ключевые запросы. Разрешаем очеловечивать их — не вписывать банально в точном вхождении.
- Указываем запросы, которые необходимо использовать на странице. Чтобы не переспамить текст оставляем только уникальные слова. Только «хвосты».
Сезонность
Если работаем в сезонной нише:
Пример — ниша «Туры для отдыха». В ней — запросы сезонные.
Собираем годовую частоту, а не месячную как это делается обычно. Если зимой будем смотреть только месячную частоту о каких-то летних турах — частота будет меньше и мы неверно оценим спрос.
Оцениваем сезонность ниши и запросов. Смотрим предварительно в Вордстате. В КейКоллекторе есть функция определения сезонности, но проще это делать через Вордстат.
В Вордстате смотрим «История запросов».
Пример — вбиваем по очереди 3 запроса: «купить золотое кольцо», «тур в Тайланд», «авиабилеты в Крым».
«Авиабилеты в Крым» — сезонность ярко выражена. Учитываем данную особенность. Закладываем её в нашу бизнес-модель. Сезонность — необходимо перекрывать спады и вовремя реагировать на пики.
Пример процесса создания ТЗ
На примере ювелирного агрегатора.
После того как запросы были собраны:
- Удаляем пустые запросы
Таким образом у нас остаётся достаточно большое покрытие нужных нам запросов и мы не будем отвлекаться на пустышки.
Пример:
Базовая частота основного запроса частотность — 8000. Отсекаем хвосты по точной частоте меньше пяти.
Мы не сможем на одну страницу запихнуть всю низкочастотку. Не нужно стараться уместить все запросы, в том числе с частоткой — 1 или 2. Иначе у нас будет спамная страница.
Примечание: Если бы у нас было не 140 запросов, а всего 20 под страницу — мы бы тогда не отсекли эти запросы. Выжимали бы по максимуму. - Удаляем по KEI
В КейКоллекторе.
KEI используют разные, но используем только один — который позволяет отсеять запросы-пустышки:
KEI = отношение базовой частоты к точной (базовая частота / точная частота).
Отсеиваем запросы с KEI более 40.
Пример:

Базовая частота 737, точная 6. KEI = 122.
Не имеет смысла использовать этот запрос при продвижении — данный запрос скорее всего высококонкурентный, но при этом даёт очень мало трафика именно в этой словоформе. - Отсеиваем по смыслу
Используем «Анализ групп» в КК. Видим — какие у нас кластеры запросов существуют и какие из этих кластеров нам интересны.
Пример:
Для коммерческой страницы нам не интересны запросы содержащие «фото». Причины:
— у нас не информационная страница,
— если на странице есть фотографии — Яндекс и Гугл и так увидят фотографии на странице,
— можем в alt’е или в подписи использовать слово «фото» и таким образом покрывать этот запрос. Например — «Источник фото: …».
Не нужно заставлять копирайтеров использовать лишние запросы.
Чтобы не было размытия ключевых слов по разным страницам — удаляем запросы, нерелевантные этой странице. Выносим/удаляем запросы, которые уже используются на других страницах. Например, у нас есть отдельные страницы под «печатки» — значит отсюда можем удалить такие запросы.
Если есть запросы, которые по частоте (спросу) достойны быть на отдельной странице — выносим их на отдельную страницу.
- Удаляем географическую привязку. Она не нужна в нашем агрегаторе.
Это удобно делать при помощи инструмента «Стоп-слова» в КК. Загружаем туда список географических привязок. Применяем сразу ко всем группам — зажав клавишу «Shift». - Экспортируем в отдельный файл все наши группы.
Чтобы экспортировать все наши группы — зажимаем «Shift».
Лишние столбцы нужно удалить. Лучше это сделать-предусмотреть ещё на этапе экспорта. В КК нажимаем на шестерёнку («Настройки») → «Интерфейс». - Когда в группе много запросов — группируем внутри группы.
Мы начинаем по определённым признакам формировать наши запросы — определяем наиболее популярные и помечаем их цветом.
Пример
Допустим — мы видим, что часто встречается слово «недорого»:
Включаем поиск — «Найти все».
Чтобы быстро кластеризировать — выделяем цветом. Для каждой группы свой цвет.
Далее — пользуемся фильтром по цвету. Это позволит быстро перенести выделенное.
Потом дорабатываем — переносим руками. - Удаляем дубли слов. Оставляем только уникальные.
Если видим что запрос плохо сформулирован для людей — не нужно бояться его просклонять и изменить. Поисковая система это поймёт. - Формируем ТЗ.
На выходе:
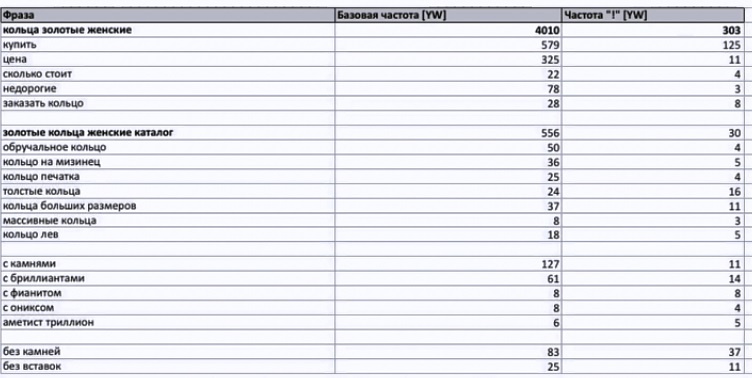
ТЗ могут быть разные.
Могут быть успешны разные сайты с разной структурой — это нормально.
Главное — какую логику Вы закладываете.
Определяем оптимальный объем текста (/статьи) на странице
Это важно для того чтобы:
- не сливать бюджет,
- получить результат,
- выработать оптимальную модель работы.
Два подхода:
- «Здравый смысл»,
- «Анализ ТОПа», он же — «аналитический».
Подход «Здравый смысл»
- Посмотреть на объём ТЗ
Посмотреть на количество блоков. Предположить что на каждый блок, который мы определяем h2, уходит около тысячи символов. Так считаем объём статьи в целом. - Далее — можем посмотреть на бюджет, который у Вас заложен на написание одной статьи с учётом размещения. Учитываем также подбор картинок либо отрисовку иллюстраций.
И исходя из этого уже понимаем — сколько готовы потратить на одну публикацию.
Но при этом нужно отдавать себе отчёт, что она может себя не окупить — просто потому что должна была быть большего размера.
Аналитический подход «Анализ ТОПа»
- Вводим нужный поисковый запрос в Гугл или Яндекс.
- Определяем количество символов документов в ТОП-10.
- Считаем среднее арифметическое.
- Пишем текст.
Объём текста — не главный параметр, но тем не менее он существенный.
Гугл очень любит когда тексты большие и им отдаёт приоритет.
Большой текст также позволяет бороться за низкочастотный трафик и бороться за ВЧ-запросы впоследствии.
Определение через бесплатный инструмент сервиса Rookee.ru
Регистрируемся. Указываем сайт. После этого:
Рекламные кампании → Запросы → Анализ страницы → Анализировать → Анализ конкурентов
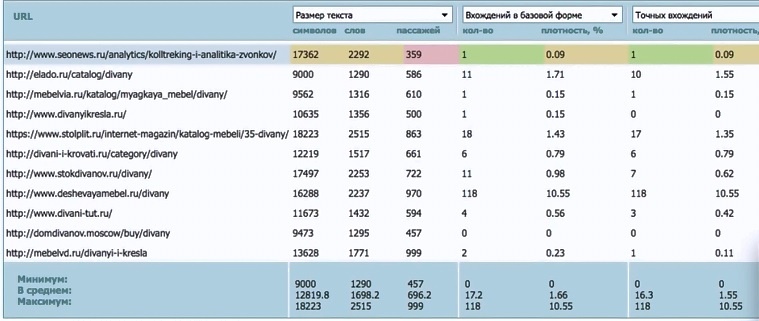
Чтобы подсчитать среднюю — откидываем «пики». Пики — самая крупная и самая мелкая страницы.
Так получаем уже достаточно грамотное среднее арифметическое.
На основе этого принимаем решение.
Не смотрим на «Вхождения», «Точные вхождения». Это не столь важно. Важно — какого уровня материал Вы подготовите, как он будет структурирован и под какую семантику.
Метод на основе здравого смысла может быть лучше аналитического.
Аналитический метод может показывать нам средний размер статьи достаточно большой. Например в примере выше — у нас более 12000 символов.
Но не всегда нужно столько писать. Если вместо огромного количества текста сделаем пару хороших таблиц и виджетов — возможно, сможем сэкономить на написании текстов и выиграть на объёме.
Поэтому перед тем как принимать решение какие тексты писать — смотрим в целом по нише несколько вариантов запросов. Разбиваем их на кластеры. Смотрим какие там тексты и на что расходуется контент (возможно контент там просто ужасный).Посмотрите вручную и затем принимайте решение.
Всегда лучше сделать более качественный контент с таблицами/виджетами нежели просто портянку текста.
Технические параметры текстов
Основные
- Объём
В RU-нете он измеряется в количестве символов без пробелов. В западном сегменте он измеряется количеством слов. - Орфографические ошибки
Используем orfogrammka.ru. Или проверяем через Word или другой инструментарий, которому доверяем. - Уникальность
Проверяем в Text.ru, Advego Plagiatus — чтобы Уникальность была более 90 процентов. Если текст технического характера — более 80.
Текст технического характера — это какие-то инструкции или медицинские статьи или ещё что-то, где тяжело как-то разбавить терминологию. У них Уникальность будет ниже.
Не нужно заставлять автора доводить до 100% Уникальности — это будет в ущерб качеству текста. - Тошнота
Тошнота — это то насколько текст переспамлен ключевыми запросами.
Смотрим в Advego — чтобы показатель «Академическая тошнота документа» был менее девяти процентов. - Частота использования слов
Смотрим Advego— чтобы была менее четырёх процентов. - Главред
В Главреде смотрим водянистые фразы и отлавливаем клише в тексте.
Особенно важно — проверить текст при первом сотрудничестве с автором.
Вторичные, но важные
- заголовок,
- подзаголовки,
- списки,
- использование различных блоков, таблиц,
- внешние ссылки.
Это бинарные показатели — их или использовали или нет. Проверяем чтобы были.
Пример проверки статьи на технические параметры
Проверяем по этой инструкции.
В Orfogrammka.ru, Advego plagiatus и Text.ru вставляем текст, запускаем проверку.
Не нужно слепо доверять Орфограммке и другим инструментам. Смотрим что они дают и их комментарии. Исходя из этого принимаем решение — корректировать статью или нет.
Проверяем в Адвего:
- показатель «Академическая тошнота текста» — в блоке «Статистика текста»,
- частоту употребления слов — в блоке «Семантическое ядро». Если самое часто употребляемое слово не имеет отношения к теме статьи — это плохо. Поисковики будут теряться и не понимать о чём у Вас текст. Обращаем на это внимание и корректируем текст.
Пример хорошей статьи — статья на Tourister.ru. Подготовив такую статью Вы всегда получите трафик потому что она максимально отвечает на запрос человека.
Плюсы:
- подробный текст,
- перелинковка,
- есть дополнительные блоки,
- подзаголовки,
- виджеты с погодой,
- вопросы, на которые можно получить ответы,
- фотографии,
- подтягивается карта,
- перечень достопримечательностей со ссылками,
- дополнительный виджет гидов,
- ссылки на авторов.
Можно подсмотреть и адаптировать под свою тематику.
Нужно учиться чтобы готовить такой контент.
Второй пример — строительная иструкция.
Плюсы статьи:
- подробная,
- отвечает на вопрос человека,
- удобная в чтении.
Разбираем статью:
- сравнительные характеристики,
- иллюстрации,
- видим выделения (или лучше бы сделать было подзаголовками?),
- структурированная информация,
- слишком большие абзацы. Их лучше разбить на несколько. Оптимально когда абзац — строк пять.
Нетехнические параметры текста
Стиль
- Для кого предназначен текст?
Для профессионалов или новичков?
Пример 1 — инструкция для «тех, кто в теме»:
1. Войдите в аппстор.
2. Залогиньтесь.
3. Скачайте.
Пример 2 — инструкция для новичков, в которой:
— 1451 слово,
— 23 фото,
— 2 видео. - Авторство статьи
Варианты авторов:
— специалисты,
— создаём персонажи,
— от лица площадки, «Noname».
Для вовлечённости аудитории лучше когда есть конкретный специалист или персонаж. - Терминология.
Структура и элементы
Чек-лист:
- абзацы не более 5 строк,
- подзаголовки h2-h4,
- таблицы,
- цитаты,
- виджеты,
- сравнительные характеристики.
Примеры инструментов повышения вовлечённости
- Пошаговые инструкции. Пример — с цифрой шага:

- Сравнение. Пример:

Разбираем пример
Информативно:
— Есть медальки — 1, 2, 5.
— Есть наиболее оптимальный «Выбор редакции» (по цене/качество).
— Есть общая оценка. Понятно какая шкала — что это 7,5 из 10-ти.
— Для каждой градации есть своё слово — «неплохо», «нормально», «средне», … .
Таким образом у нас есть возможность задержать человека на странице — он больше вовлечётся и проведёт больше времени. Благодаря этому — наша страница выигрывает у конкурентов.
- Опрос. Позволяет повзаимодействовать — сделать дополнительные клики.
Пример:

- Медальки при сравнении. Пример:

Разбираем пример
Цифры — означают место.
Цвет круга соответствует месту — Золото, Серебро, Бронза.
Шрифты
Важны:
- шрифт,
- цвет шрифта,
- размер шрифта — удобный для чтения,
- цвет фона.
Это влияет на удобство восприятия.
Чтобы выбрать шрифт — смотрим на сайты именитых конкурентов.
Использовать лучше всего классический вариант — чёрный шрифт на белом.
Пример — Vc.ru:
- удобные крупные шрифты,
- чёрные буквы по белому фону,
- всё хорошо структурировано.
Инструкция по написанию статей — для копирайтера
Пример — Инструкция по написанию статей.
Структура инструкции
- Цель
Цель должна быть понятна, чтобы автор понимал на чём делать акценты. - Технические характеристики
Уникальность, Тошнота и другие метрики. - Элементы ТЗ
Подробности — чтобы уменьшить взаимодействия между автором и редактором. - Требования к структуре
Учим автора использовать теги h1-h4. Учим размечать подзаголовки — в GoogleDocs или в Word’е (в зависимости от того где нам удобнее работать).
Когда научим — нам будет проще верстать статью. Проще будет работать контент-менеджеру с входящим материалом. - Требования к содержанию
Перечисляем пункты, которые мы хотим видеть в статье.
Это могут быть:
— таблицы,
— определённые сравнительные характеристики товаров,
— другие задумки, полезные для читающего статью. - Примеры статей
Всегда указываем примеры статей. Примеры могут быть как на нашем сайте так и на других ресурсах.
Показываем:
— то что уже максимально соответствуют нашим ожиданиям,
— видение того что мы хотим видеть на своём сайте,
— что хотим донести до читателя. - Сервисы для оценки качества
Сервисы для проверки технических характеристик.
Дополнительно можем указать:
- специфические элементы, которые обычно не предусмотрены в других статьях,
- источники,
- виджеты.
Фотографии
Какие фото брать?
Технические параметры фотографий:
- Разрешение
Регламентируем — чтобы фотографии не были со слишком маленькими. Для этого нужно посмотреть какой у нас размер контентной части. Обычно это 700-800 пикселей. - Вес
Вес фотографий влияет на скорость работы сайта. Если на сайте нет функционала, который будет обжимать фотографии и делать их легче — то это необходимо делать контент-менеджеру на этапе добавления. - Соотношение сторон
Это больше к стилю. Желательно регламентировать приведя к единому стилю.
Где взять фото?
Платные источники
- Фотохостинги. Например — Depositphotos.com, Shutterstock.com),
- Каталог фотографий Etxt.ru.
Бесплатные источники
- Бесплатные фотохостинги. Подборка из 36 источников.
- Сообщества.Например — Tumblr.com, Flickr.com, Instagram.com
Можем искать по тегам, по поисковым запросам. Но при этом способе — ставим ссылку на источник. - Официальные фото.
Пример — ссылка на источник:

На этом примере — ссылка «SOURCE» в nofollow.
Используем зарубежные фотографии
- Переводим ключевой запрос на английский, немецкий, испанский.
- Ищем фото в Google Images.
- Используем и ставим ссылку.
Уникализируем фотографии
- изменяем размер (разрешение),
- обязательно изменяем название физического файла,
- если фотографии наши — добавляем копирайт,
- добавляем подписи,
- прописываем alt.
Роль структуры (семантического проектирования) в прототипировании сайта
Автор— Игорь Рудник.
Структуру сайта необходимо составлять перед прототипированием.
Прототипирование обычно делается для крупных проектов со сложной структурой.
Эта история не для обычного статейного сайта с двумя уровнями уровнями вложенности. Скорее это для маркетплейса или интернет-магазина с разветвлённой структурой — когда необходимо продумать какая будет структура, какие будут блоки перелинковки.
Структура сайта регламентирует:
- виды страниц (рубрики, информационные, карточки товаров),
- количество уровней вложенности страниц,
- структуру страниц,
- количество разделов,
- количество страниц,
- способность к масштабированию.
Зачем?
- уменьшение времени разработки,
- удешевление разработки проекта,
- уменьшение потенциального количества ошибок,
- повышение вероятности положительного результата.
Типичные ошибки
- не заложили нужное количество уровней вложенности страниц,
- не заложили фильтры и способ их работы (Какие из них индексируются под семантику, а какие просто для удобства пользователей),
- не спроектировали адреса страниц и их уровни вложенности (Продумываем ЧПУ, как они будут выглядеть, с какими уровнями вложенности),
- не посчитали количество разделов,
- не масштабируемый дизайн.
Перелинковка
- заклыдываем на прототипах,
- просчитываем количество внутренних ссылок на странице,
- закладываем управление блоками автоматической перелинковки.
Как делать прототипы (минимально достаточные прототипы)
Десктоп
- Axure (самый лучший инструмент)
- Balsamiq.com
Онлайн
Итоговая документация
- структура (в XMind’е),
- прототипы,
- описание автоматической перелиновки.
Пример прототипа
Вот так выглядит простейший прототип:
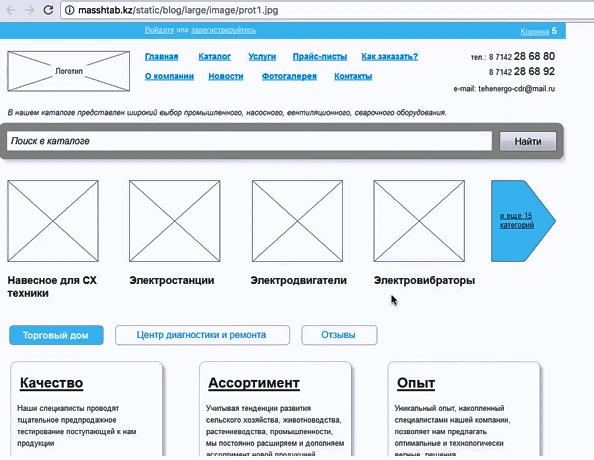
Блочно обозначено — где какие данные будут.
Что как будет работать — нужно прописать в ТЗ. Но это нужно делать после создания структуры.
Примеры хорошей структуры
LSI-тексты
Автор— Сергей Кокшаров (Devaka).
Введение
- Модель векторных пространств
- Латентно-семантический анализ
+ Англоязычная статья в Википедии, в которой больше информации чем в русской версии. - Тематическое моделирование
Методы получения LSI-фраз
- Анализ спроса,
- Анализ текста,
- Анализ семантических связей.

Анализ спроса
- Поисковые подсказки,
- Рекомендации в поиске,
- Яндекс.Вордстат (или Google Keyword Planner).
Поисковые подсказки
- Идём в Яндекс и вбиваем свой ключевой запрос в поисковую строку.
- В поисковой строке видим всплывающие подсказки.
- Дополнительные слова из подсказок выписываем в Excel.
- Смотрим также и в Google.
Если запросов много: используем инструменты — КК, Серпстат или др.
Помечаем источник — откуда эти данные:
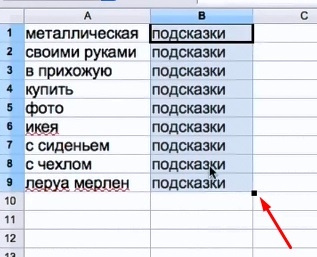
Вносим только те, что нам подходят.
Рекомендации в поиске
Рекомендации — внизу выдачи в виде ссылок. Это информация о том что чаще всего ищут вместе с этими запросами:
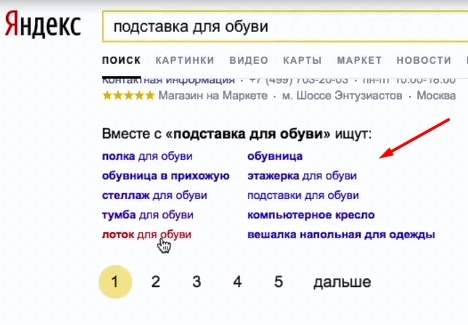
Нам интересны слова, которые выделены жирным. Те что не выделены жирным — являются частью запроса.
Смотрим в Яндексе. Потом в Google.
Если мы не затачиваем под какой-то конкретный регион — фильтруем региональные элементы спроса.
Яндекс.Вордстат (или Google Keyword Planner)
Яндекс.Вордстат или Google Keyword Planner? Вордстат в этом плане получше и поудобнее.
Левая колонка Вордстата больше отражает подсказки, а правая — рекомендации.
Если видим, что словосочетание сильное (пример — «ювелирный магазин»), то пишим его. А если видим что это просто разные слова (пример — «обувница прихожая»), то необязательно писать их вместе.
Анализ текста
- На выдаче,
- Тексты сайтов.
На выдаче
Недостаток — небольшой кусок текста, не всегда даёт качественный результат.
Инструменты:
- Арсенкин
Выбираем ТОП-20, так как по ТОП-10 очень мало данных, а по ТОП-50 очень много шума.
В результатах смотрим «Слова, задающие тематику(лемматизированные)».
Можем проверить и по другому региону — чтобы посмотреть будут ли дополнительные слова. - Пиксель-Тулс
Не даёт словосочетания — только слова. Этих слов недостаточно. Поэтому мы используем не этот один инструмент, а комплекс инструментов.
Тексты сайтов
Недостаток — может присутствовать лишняя информация, которая не касается текстов. Лишняя информация — техническая, «Добавить в корзину».
Инструменты:
- Текстовый анализатор Textanalyzer.ru
Самое оптимальное будет добавить текст с нескольких сайтов — смотрим ТОП3. - «SEO-анализ текста» Мегаиндекс
Если выдаёт много слов — просматриваем 20 первых. Остальные чаще всего не подходят. - Ultimate Keyword Hunter
Уникальная программа, которая может заменить другие инструменты.
Работает с любой семантикой на любом языке.
Не работает с морфологией. Пример — «подходить» не будет зачтено как «подходить».
Сохраняем настройки по умолчанию — до 4-х слов и до 10-ти сайтов;
Если данных недостаточно — задаём 20 сайтов.
Фильтруем — ставим критерии 2 и 1. Это означает — минимум два раза повторяется минимум на двух сайтах.
Начинаем с многословников. Берём те фразы которые естественно выглядят.
Вкладка «4. Preview» позволяет подгрузить собранные слова и сверить их упоминания в тексте. Мы вводим слова и они вычёркиваются в тексте.
Если видим, что какие-то слова (/фразы) не использовались — можем прям здесь же отредактировать.
Вылавливаем коллокации — устойчивые словосочетания, которые часто используются в этой тематике.
Анализ семантических связей
Инструменты:
- Акварель-генератор от Алексея Чекушина
Этот сервис учитывает пассажную близость — насколько близко расположены слова к заданному ключевому слову. Другие (упомянутые ранее) инструменты этого не делают.
- Word2vec
Можно собрать из нескольких источников текст, обучить нейронную сеть и уже потом простыми командами получать необходимые связки.
Нужно дополнительно обучаться + нужна начальная выборка.
Пригодится когда есть глобальные задачи и возможность самим программировать.
Это сложный инструмент. Не все его смогут применить. Поэтому мы и рассматривали другие методы и инструменты — более простые.
LSI Graph для англоязычной семантики
Минимальный набор, который понадобится
- Ultimate Keyword Hunter,
- Акварель-генератор,
- Арсенкин (или ПиксельПлюс).
Этих трёх инструментов для большинства случаев более чем достаточно.
- Если работаем с англоязычной семантикой — LSI Graph.
Если любим тщательную проработку:
- Используем все источники.
- Делаем по ним сводную таблицу в Excel.
Excel
После сбора в Excel данных из всех источников — используем «Сводная таблица» для подсчёта пересечений. Считаем сколько раз употребляется в разных источниках. Один источник =1.
В первых двух-трёх абзацах стараемся использовать топовые LSI-фразы (/слова). Топовые — те, у которых больше всего пересечений по источникам.
Проверка пользы по LSI
Польза по LSI — это отношение LSI-фраз к общему количеству уникальных слов:
- меньше 10-ти — плохо,
- от 10 до 20 процентов — хорошо,
- больше 20-ти — супер.
Чем более человек профессионал, тем он сам больше употребляет LSI-фразы(/слова). Это для него естественно.
LSI-фразы(/слова) достаточно использовать один раз. Но если встречаемость больше — не страшно.
Нужно также проверять — нет ли предложений где вообще нет никаких фраз из основного или LSI-ядер. Каждое предложение должно содержать в себе ключевое слово из семантического (основное ядро) или из околосемантического (LSI) ядра. Если будут присутствовать предложения, которые не содержат фраз(/слов) из того или иного ядра — то это бесполезное предложения, которые наоборот снижают релевантность текста по основной ключевой фразе.
Правило — чем длиннее текст, тем больше фраз мы должны иметь в околотематическом ядре.
Полезный инструментарий
Автор— Игорь Рудник.
- Advego,
- ContentYoda,
- Text.ru,
- Главред.
Advego
Чем полезен:
- Проверка орфографии
Есть также хороший второй альтернативный сервис — Орфограммка. В нём можем получить полезные комментарии, замечания, предлагаемые корректировки. - Семантический анализ текста
Смотрим:
— На «Академическую тошноту документа» — чтобы была меньше 9%.
— На наиболее часто используемые слова — в блоке «Семантическое ядро». Они должны соответствовать тематике текста. - Проверка уникальности текста — программа Advego Plagiatus.
ContentYoda
Сервис для анализа текстов.
Доступна бесплатная версия.
Функционал:

Text.ru
Проверка уникальности.
Можно сразу посмотреть орфографию.
Главред
Оценка показывает общую картинку по тексту по:
- информативности,
- «воде»,
- структуре самих предложений.
Не стоит слепо доверять всему и всё исправлять. Но он помогает выработать стиль, который более удобно читать.
Углубленный анализ конкурентов (при помощи Serpstat или другого аналогичного инструмента)
Автор— Игорь Горбенко (представитель Serpstat).
Релевантность (или близость нас конкуренту) зависит от того:
- Сколько общих фраз есть у нашего сайта и у конкурента.
- Какой объём от всех ключевых фраз эти фразы занимают на сайтах.
Пример — анализ конкурентов в Serpstat
Пример — в Serpstat. «SEO-анализ» → «Конкуренты».
Релевантность — самый важный параметр. Сортируем сайты по релевантности — выводим вверх списка те сайты, которые ближе всего всего нам по семантике.
Другие интересные данные в отчёте:
- количество общих ключевых фраз,
- количество отсутствующих фраз.
Отсутствующие фразы — это те что есть у конкурента и не были найдены на нашем сайте. Отсутствующие фразы, потенциально, — это расширение ядра.
Переходим к детальному анализу конкурентов из списка:
- Начинаем с «Поддомены» — смотрим куда ещё конкурент ведёт трафик.
- Потом смотрим в «Страницы сайта» — страницы сайта конкурента:
— которые приносят больше всего трафика,
— которые ранжируются по самому высокому количеству ключевых фраз,
— у которых самый высокий потенциал.
Этот отчёт нужен нам для того чтобы посмотреть как устроены те страницы, которые приносят больше всего трафика конкуренту. - В отчёте «Дерево сайта» — карта релевантности сайта со списком фраз для каждой страницы сайта. Используем фильтры.
Кластеризация запросов
Автор— Сергей Кокшаров (Devaka).
План:
- Теория,
- Сервисы,
- Практика — проверка совместимости запросов.
Теория кластеризации
Необходимость группировки:
- Помогает в поиске схожих объектов.
- Работа с группами проще, чем работа с сырыми данными.
- Можно находить нетипичные объекты.
- Помогает выстраивать иерархию множества.
Для сайта это поможет:
- Сформировать структуру (раздела или сайта).
- Оптимизировать текущую структуру.
- Искать, находить и работать с потенциально сильными кластерами
Потенциал кластера — суммарная частотность всех запросов + учитываем конкуренцию. - Проверять совместимость продвигаемых запросов.
Группировка бывает двух разных типов:
- Классификация,
- Кластеризация.
Классификация:
- обучение с учителем — обучение на выборке,
- известно количество групп (геозависимые/геонезависимые),
- используется для классификации будущих наблюдений.
Кластеризация:
- обучение без учителя,
- неизвестно количество групп,
- используется для понимания данных.
Кластеризация по ТОПу поисковой выдачи
- Снимается список страниц в ТОП10 по заданным запросам.
- Подобие выдачи по разным запросам — формирует кластер.
Подобие выдачи — подразумевает, что мы нашли синонимы или фразы одного интента. - Степень и правила подобия формируют различные методы кластеризации.
Методы кластеризации по ТОПу
Soft-кластеризация
Количество общих страниц в ТОП10 превышает заданный порог. Порог определяем сами. Обычно — 4-5 документа.

Soft-кластеризация даёт группы большего размера, но часто ошибается в возможности совместного продвижения запросов. Три запроса попадут в одну группу если в ряде страниц есть пересечения первого и второго запроса, а на других страницах второго и третьего. Хотя они и будут в одной группе — между первым и третьим запросами прямой связи может и не быть.
Soft подходит для трафиковых проектов. Это когда не создаём кучу статей, а делаем статью максимально большой.
Hard-кластеризация
Имеется общий набор страниц (3-4), который по всем запросам показывается в ТОП10.
Три запроса попадут в одну группу только если будут пересекаться все три по одним и тем же URL-ам.
Hard подходит для вывода на странице только определённого набора запросов.
Используем для коммерческих проектов.
Проблемы кластеризации по ТОПу
- Сложно измерять эффективность кластеризации.
- Необходимы дополнительные классификаторы — Гео и Коммерческость.
В один и тот же кластер могут попадать запросы коммерческого типа и информационного типа. А мы не можем создать одну страницу и под коммерческий и под информационный запрос — классификатор Яндекса определит к чему-то одному.
Для коммерческих сайтов желательно использовать Hard-кластеризацию, где мы исключаем необходимость дополнительно подключать классификатор коммерческости. - Проблема главных страниц — нет смысла продвигать на внутреннюю страницу те запросы, по которым вся выдача состоит из главных страниц или наоборот.
- Встречаются случаи, когда фразы могут попадать в разные кластеры с одинаковой вероятностью. Это зависит от последовательности проверки.
- ТОП постоянно меняется.
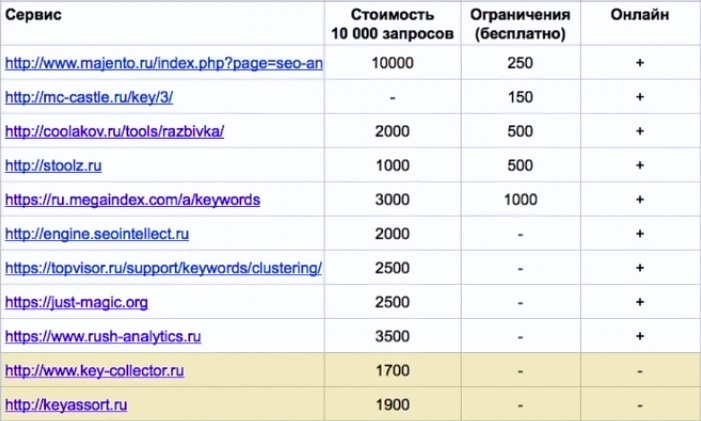
Сервисы кластеризации
Практика — проверка совместимости запросов
Проверяем совместимость запросов — «Мобильные телефоны», «сотовые телефоны», «смартфоны».
Смотрим «купить мобильные телефоны», «купить сотовые телефоны», «купить смартфоны» — в «Выгрузка ТОП-10» Арсенкина:
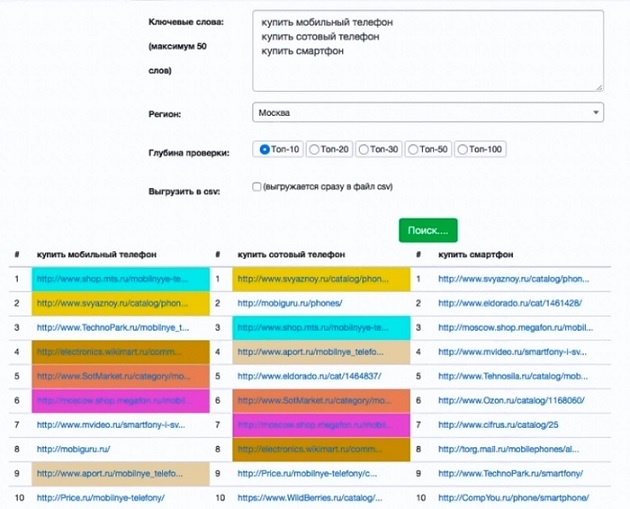
Рассматриваем страницы:
- в Связном — первую по «купить сотовый телефон» и первую по «купить смартфон». Это две разные страницы, на которых выводится всё то же. Но с единственной разницей — на одной подставляется «Смартфон», а на второй «сотовой телефон».
- у Эльдорадо тоже две разные страницы под эти запросы. Но содержимое разное — на одной кнопочные телефоны, а на второй смартфоны.
Также проверяем шесть запросов в десктопной КейАссорт:
- «мобильные телефоны»,
- «сотовые телефоны»,
- «смартфоны»,
- «купить мобильные телефоны»,
- «купить сотовые телефоны»,
- «купить смартфоны».
В ПиксельТулс проверяем совместимость на коммерческость — все шесть запросов с помощью инструмента «Геозависимость, локализация и коммерциализация»:

С точки зрения коммерческости — они совместимы, но не совместимы с точки зрения кластеров.
После работы кластеризатора — нужно обязательно просматривать результаты, работать руками.
Если видим запросы формата «ТОП10 умных пород собак» и в выдаче уже есть подобный ТОП10. Нужно чем-то отличиться — делаем ТОП12 (/ТОП20).
JustMagic и RushAnalytics — более профессиональные сервисы. Они позволяют задавать различные настройки — чтобы сразу кластеризацию немножко подкорректировать. Благодаря этому потом будет меньше ручной работы.
Например:
- В RushAnalytics:
— можем отфильтровать геозапросы по определённому городу,
— добавить стоп-слова по тематикам. - В JustMagic:
— можем увидеть количество морд в ТОПе,
— можем фильтровать по количеству морд или тематике.
Выбор автора
Автор— Игорь Рудник.
План:
- Введение.
- Где искать.
- Текст вакансии для поиска автора.
- Тестовая задача копирайтеру.
Введение
Виды текстов:
- тексты для интернет-магазинов,
- статьи для контентных сайтов,
- для корпоративного блога,
- для контент-маркетинга.
Правильные авторы:
- Не пишут “копирайтерским языком”.
- Имеют практический опыт в теме.
- Обучаемы.
Чтобы можно было до них донести информацию. Например — что нужно работать в ГуглТаблице. Или что нужно использовать подзаголовки, определённые форматы, стили. Без такой стандартизации тяжело выстроить процесс написания серьёзных текстов. - Ответственные и пунктуальные.
Критерии выбора авторов:
- знание русского языка,
- профильное образование,
- адекватность,
- коммуникабельность.
Где искать
Традиционные каналы
- биржи контента — etxt.ru, advego.ru, contentmonster.ru,
- агентства копирайтинга,
- фриланс-биржи.
Альтернативные источники авторов
- знакомые,
- паблики и группы — ВК, ФБ, ОК,
- сайты работы — hh.ru, superjob.ru, careerist.ru,
- профильные форумы.
Пример — поиск кровельщика
Используем:
- Сайты работы.
- Биржи — etxt.ru, advego.ru, contentmonster.ru или др.
Contentmonster.ru удобен что есть каталог авторов по тематикам и можем им написать. - Социальные сети.
Фильтруем группы по нужному ключевому слову. Связываемся с ними и договариваемся о размещении.
Не смотрим на то что это стоит денег — зато это выигрывает время. - Сообщества — https://professionali.ru/ и др.
Отфильтровываем по слову «кровельщик». С ними можно связаться и спросить интересна ли им позиция по написанию статей.
Можно зайти в классифайды-рубрикаторы мастеров по ремонту. Отфильтровываем по нужной рубрике, в данном случае — «Кровельные работы». И так же связываемся с людьми через сообщения или телефон. - Профильные форумы.
Не старайтесь закрывать позиции (особенно нестандартные) только через биржи контента. Ищите через сообщества — там, зачастую, более крутые авторы.
Пример размещения вакансии на сайте работы
Пример — без специализированного поиска:
Разместили вакансию и старгетировали её на Нижний Новгород. На Нижний Новгород — с той целью что в регионах дешевле чем в Москве или в Санкт-Петербурге.
Но стоит учитывать что при размещении в регионе — отклик людей меньше. Тут нужно расставить приоритеты что важнее — быстрее закрыть вакансию или уменьшить расходы.
Текст вакансии для поиска автора
Первичные элементы текста:
- Приветствие (всегда здоровайтесь).
- Тематика.
- Форма сотрудничества — удаленно или в штате.
Вторичные элементы:
- стоимость,
- форма оплаты,
- объемы работы.
Разные площадки — разные объявления
На биржах контента и сайтах работ — одни объявления. А в сообществах (ВК, ФБ, ОК и на форумах) — другие.
Размещение на биржах контента и сайтах работ
Эта же заявка когда в заголовке было просто «Копирайтер» собрала значительно меньше откликов. Конкретика в заголовке оказалась важна. В заголовке обязательно пишим тематику.
Тестируйте заголовки.
Размещение в сообществах
Пример — размещение в паблики:
Отклик у первого объявления был слабый. В нём была фраза — «Отметьтесь в комментариях и мы с вами свяжемся». Отклик у первого объявления был слабый — потому что люди не любят отмечаться, что они ищут работу.
Тестируйте
- Не размещайте повторно одинаковые вакансии (как минимум меняйте заголовки).
- Меняйте заголовки.
- Меняйте таргетинг вакансий.
Тестовая задача копирайтеру
Составляем тестовую задачу копирайтеру:
- цель сайта,
- цель написания текста,
- ТЗ на текст,
- примеры,
- инструкция автора.
Тестирование авторов:
- Пробная задача (оплачиваемая).
- Редакторская вычитка.
- Стилистическое соответствие.
- Оформление.
- Структура.
- Пунктуальность.
- Оцениваем нашу коммуникацию.
Налаживание взаимодействия:
- Контакты.
- Облачный файл-обменник.
- Таск-менеджер.
Пример:

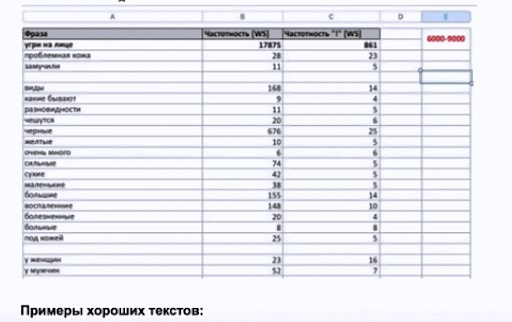


Таблица для ведения учёта
Пример таблицы для ведения учёта. Это сводная таблица по всем авторам.
Данные — в столбцах A-T.
Приучаем авторов заполнять эту таблицу самостоятельно — для них есть отдельная таблица со столбцами A-J. Данные из неё подтягивается в нашу сводную таблицу по всем авторам.
P.S. На официальной странице курса заявлен ещё один раздел — «Создание семантики для зарубежных проектов». Когда проходил курс — его не было. Соответственно — его нет в конспекте.
Спасибо за курс Игорю Руднику (создатель collaborator.pro, seoenergy.org, referr.ru), Сергею Кокшарову (devaka.ru) и Игорю Горбенко.
Спасибо Ринату Хайсману за публикацию моего конспекта.
С уважением, Александр Сопоев.