

В предыдущей статье я описал процесс сбора маркерных запросов так, как это делаю я, но методик столько, сколько специалистов на рынке: каждый делает по-своему. Для того, чтобы показать процесс сбора маркеров со всех сторон, я провел небольшой опрос SEO-специалистов.
Подписывайтесь на телеграм-канал SEO-специалисти узнавайте первыми всю актуальную информацию по самостоятельному продвижению сайтов.
Если вы только начинаете познавать SEO, рекомендую ознакомиться с основными SEO терминами.
1. Павел Ревуцкий, prdigital.pro
Шаг 1: Определяю структуру запроса
Если я подбираю ключевые слова для конкретной страницы, то в первую очередь определяю структуру запроса. Это позволяет сразу сузить итоговый список ключевых слов, что существенно сэкономит ресурсы на чистку и кластеризацию. Рассмотрим на примере двух предполагаемых тем:
- Как создать приложение для вызова такси;
- Применение больших данных в финтех индустрии;
В первом случае запрос будет состоять из трех частей:
- Спецификатор, определяющий интент — “создать”
- Тело, часть 1 — “такси”
- Тело, часть 2 — “приложение”
Во втором случае — из двух:
- Тело, часть 1 — “большие данные”
- Тело, часть 2 — “финтех”
Как видно, [wpdiscuz-feedback id=»bmsj8tb2pd» question=»Есть мысли по этому поводу?» opened=»1″]под разный интент может быть разная структура запросов[/wpdiscuz-feedback]. Далее, для упрощения, я буду показывать алгоритм на примере первой статьи.
Шаг 2: Нахожу синонимы для каждой части запроса
Сначала задействуем свой словарный запас, а затем — переходим к исследованию выдачи по маркерному запросу.
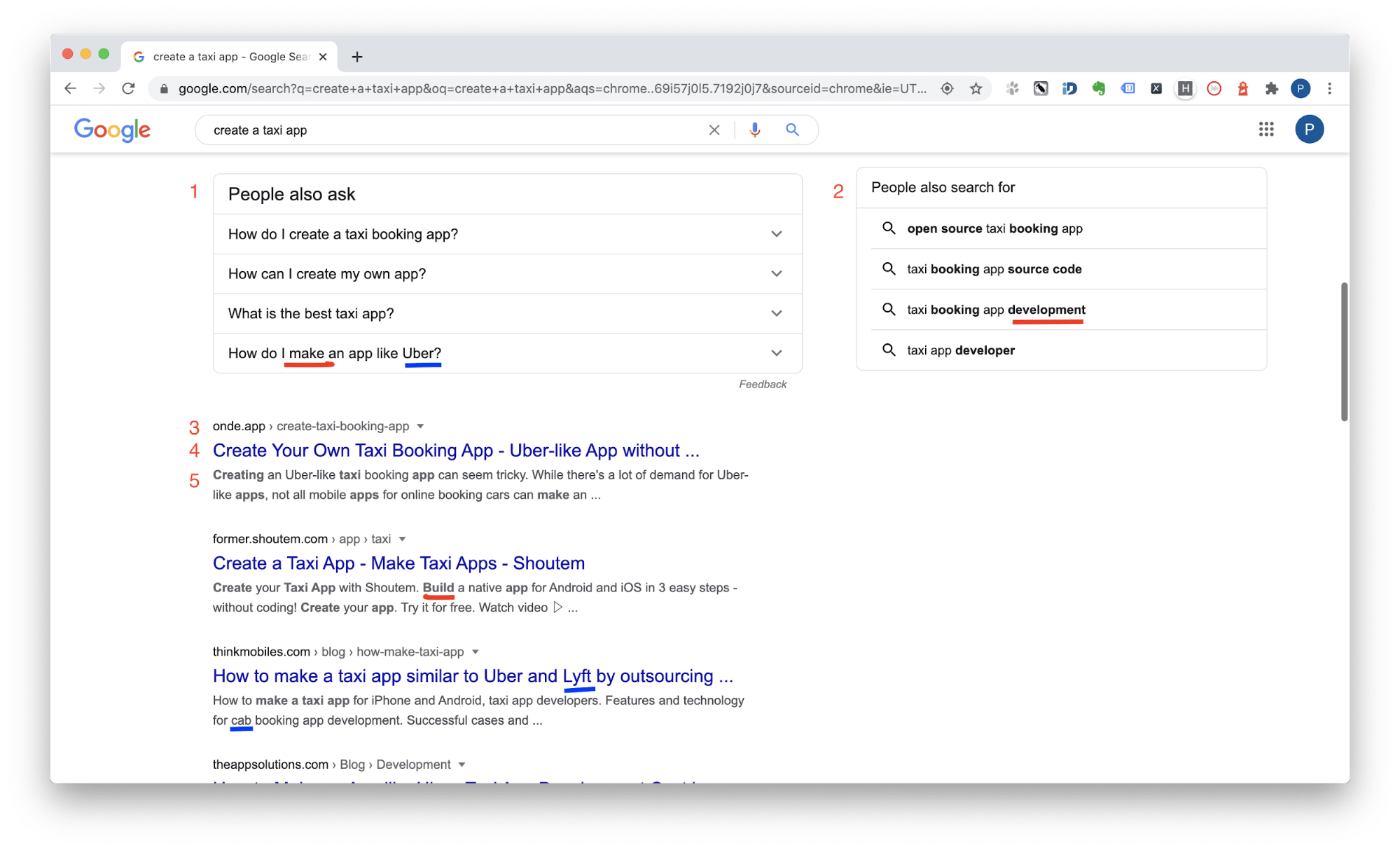
Элементы, на которые следует обращать внимание:
- Блок “People also ask”;
- Блок “People also search for”;
- Хлебные крошки и URL;
- Title в сниппете;
- Description в сниппете, особенно подсветка.
Как правило, этой информации уже достаточно, но если углубиться, то можно также исследовать title, h1-h6 конкурентов и поисковые подсказки, а при продвижении русскоязычных запросов — правую колонку Wordstat. Также не помешает воспользоваться сервисами конкурентной разведки по URL, если у вас есть к ним доступ. Например, Organic Search Positions в Semrush.

На примере статьи по разработке приложения для такси мы получили 3 массива данных:
| Массив 1 | Массив 2 | Массив 3 |
| create | taxi | app |
| make | cab | application |
| build | uber | |
| develop | lyft | |
| start | ||
| design |
Шаг 3: Генерирую маркеры
Чтобы получить маркеры для парсинга ключевых слов, необходимо проитерировать массивы и сцепить слова. Для этой задачи я использую простейший скрипт на Python.
Итоговый результат:

Ну а дальше — парсинг, чистка, кластеризация. Вполне вероятно, что у некоторых маркеров будет слабая связь с основным кластером. Это определится на этапе кластеризации
2. Айрат Рахимзянов, @seosekretiki
При проработке семантического ядра всего сайта или какого-либо конкретного раздела я не выделяю работу с маркерами как отдельную задачу. В качестве маркеров могу брать всё, что относится к тематике сайта. Собираю все запросы из всех популярных источников (вордстат, метрика, панель вебмастера Яндекса, GSC и аналитикс, keys.so, подсказки и т.д.) и загружаю их в Key Collector. В самом же КК есть группировка по отдельным словам:

… чтобы в общей каше найти сгруппированные запросы по нужным вам маркерам.
Для примера. Есть интернет-магазин продающий продукцию от компании Apple, в структуре есть подразделы типа iPhone и iPad, соответственно для каждого из них базовыми маркерами для парсинга запросов на входе будут следующие фразы: apple и все производные варианты, аля “эппл” или “эйпл”. Тоже самое и с iPhone (айфон) и iPad (айпад). Если есть какие-то уточняющие моменты, то задаем сразу их. Если магазин занимается только продажей продукции, а сервисным обслуживанием не занимается, тогда можно собирать только те запросы, которые содержат в себе слово “купить”, “продажа, “цена” или “стоимость”, где явно задается логика для поиска коммерческих запросов, дополнительно сразу при помощи списка стоп-слов можно отсекать не подходящие для нашей тематики запросы.
Тоже самое и для информационной тематики, можно сразу же задавать маркерные слова типа: “как”, “где”, “когда”, “что” и т.п. Где явный интент будет информационным.
Отдельно отмечу, что есть запросы типа volkswagen, вариаций к этому запросу может быть огромное количество. Можно сразу в голове прикинуть маркерные запросы (с какими словами могут искать то, что нам нужно?). Это могут быть запросы: vw, фв, фольксваген, фольцваген, wolsvagen, фольсваген, вольксваген, вольцваген, вольтсваген, фольсфаген и т.д. Такие запросы чаще всего можно выгрузить у конкурентов (например, с помощью сервиса keys.so, при помощи групповых отчетов или дополняющих фраз):
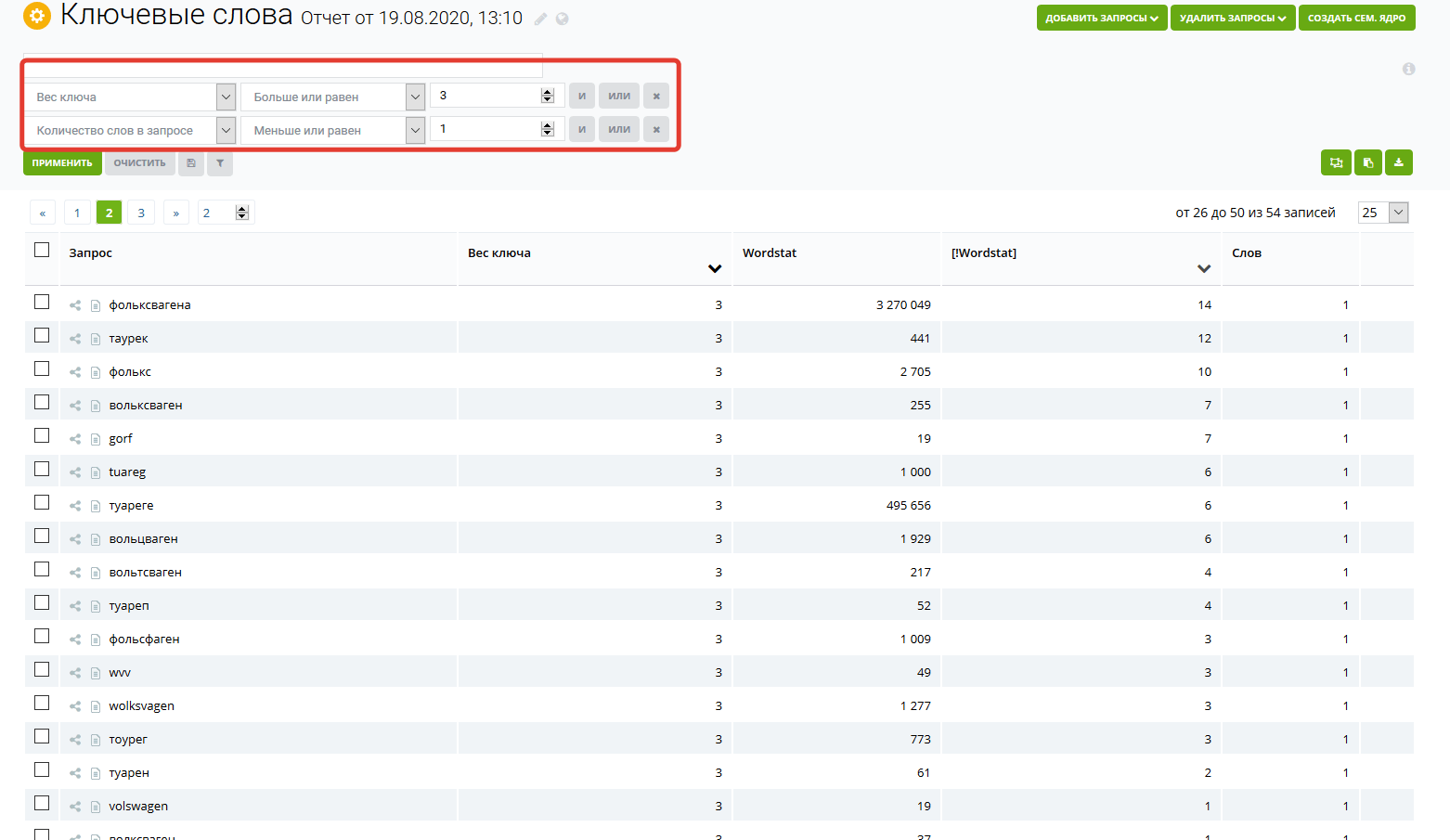
Тоже самое и с другими маркерами типа “недорого”, “дорого”, “дешево”«. Такие запросы можно продвигать на страницах сортировок цены (по убыванию или возрастанию). Пример реализации можно посмотреть на странице:


Для тех, кто любит продвигаться по брендовым запросам, можно пробовать парсить запросы по маркерам типа «официальный сайт» и т.п. Очевидно, что в каждой тематике будут свои маркерные запросы.
Также после сбора всех возможных фраз (по маркерам или просто из всех баз) можно находить между ними синонимы, о которых даже не мог изначально предполагать, описывал это тут.
3. Артем Высоков, vysokoff.ru
Подготовка к сбору семантического ядра начинается со сбора маркеров или, как я называю, со сбора первичной семантики. Сбор маркеров проходит в несколько этапов.
- Генерируем первичные ключи из головы.
- Общаемся с экспертами отрасли (или владельцами сайта), чтобы они подкинули какое-то количество специфических фраз из ниши.
- Вбиваем основные ключевые фразы в Wordstat и анализируем правую колонку с целью найти синонимы и другие тематикообразующие фразы.
- Смотрим Википедию по основным ВЧ-запросам, чтобы найти дополнительную первичную семантику для парсинга.
- Анализируем 3-5 конкурентов из ТОПа, чтобы найти у них уникальную экспертную семантику. Загоняем эти сайты в Keys.so или Букварикс и снимаем семантику конкурентов.
- Собираем запросы из раздела под поисковой выдачей в Яндексе «Люди ищут» и в Google «Вместе с %запрос% часто ищут».
Получив всю первичную семантику и добавив очищенную от мусора семантику конкурентов, начинаем парсить.